Written by: Saurabh Rai
Boost Your AI with These Top Open Source Retrieval Augmented Generation (RAG) Libraries

Retrieval Augmented Generation (RAG) enhances AI by combining data retrieval with response generation, allowing models to pull in external information for more accurate, context-aware answers. This approach empowers developers to build flexible, data-driven AI solutions. Discover top open-source RAG libraries to elevate your AI’s capabilities.
Retrieval Augmented Generation (RAG) is an AI technique that combines searching for relevant information with generating responses. It works by first retrieving data from external sources (like documents or databases) and then using this information to create more accurate and context-aware answers. This helps the AI provide better, fact-based responses rather than relying solely on what it was trained on.
RAG (Retrieval-Augmented Generation) works by enhancing AI responses with relevant information from external sources. Here’s a concise explanation:
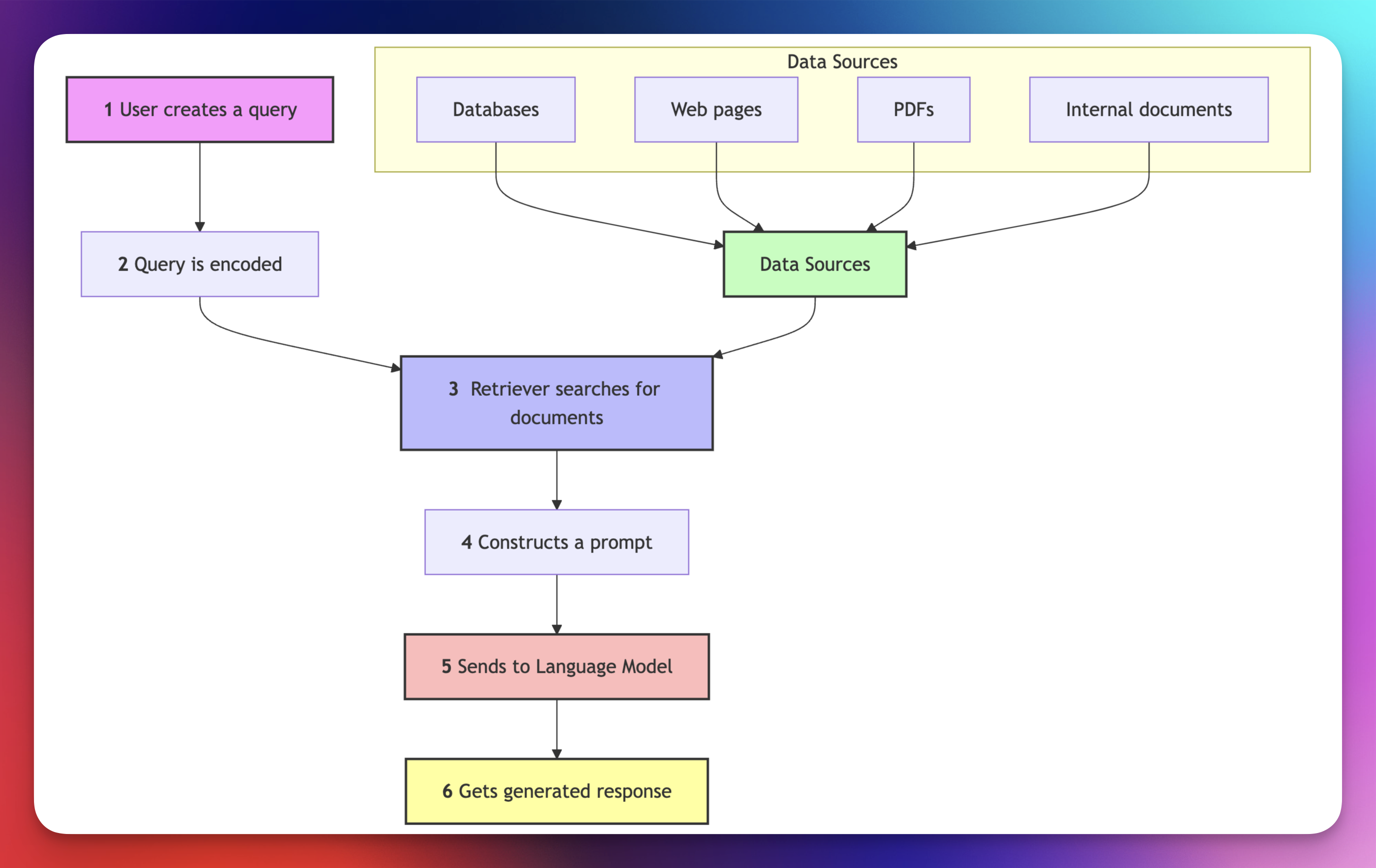
RAG makes the AI more reliable and up-to-date by augmenting its internal knowledge with real-world, external data. RAG also improves an AI model in a few key ways:
Let’s explore some open-source libraries helping you do RAG. These libraries provide the tools and frameworks necessary to implement RAG systems efficiently, from document indexing to retrieval and integration with language models.
 SWIRL is an open-source AI infrastructure software that powers Retrieval-Augmented Generation (RAG) applications. It enhances AI pipelines by enabling fast and secure searches across data sources without moving or copying data. SWIRL works inside your firewall, ensuring data security while being easy to implement.
SWIRL is an open-source AI infrastructure software that powers Retrieval-Augmented Generation (RAG) applications. It enhances AI pipelines by enabling fast and secure searches across data sources without moving or copying data. SWIRL works inside your firewall, ensuring data security while being easy to implement.
What makes it unique:
🔗 Link: https://github.com/swirlai/swirl-search
 Cognita is an open-source framework for building modular, production-ready Retrieval Augmented Generation (RAG) systems. It organizes RAG components, making it easier to test locally and deploy at scale. It supports various document retrievers, embeddings, and is fully API-driven, allowing seamless integration into other systems.
Cognita is an open-source framework for building modular, production-ready Retrieval Augmented Generation (RAG) systems. It organizes RAG components, making it easier to test locally and deploy at scale. It supports various document retrievers, embeddings, and is fully API-driven, allowing seamless integration into other systems.
What makes it unique:
🔗 Link: https://github.com/truefoundry/cognita
 LLMware is an open-source framework for building enterprise-ready Retrieval Augmented Generation (RAG) pipelines. It is designed to integrate small, specialized models that can be deployed privately and securely, making it suitable for complex enterprise workflows.
LLMware is an open-source framework for building enterprise-ready Retrieval Augmented Generation (RAG) pipelines. It is designed to integrate small, specialized models that can be deployed privately and securely, making it suitable for complex enterprise workflows.
What makes it unique:
🔗 Link: https://github.com/llmware-ai/llmware
 RagFlow is an open-source engine focused on Retrieval Augmented Generation (RAG) using deep document understanding. It allows users to integrate structured and unstructured data for effective, citation-grounded question-answering. The system offers scalable and modular architecture with easy deployment options.
RagFlow is an open-source engine focused on Retrieval Augmented Generation (RAG) using deep document understanding. It allows users to integrate structured and unstructured data for effective, citation-grounded question-answering. The system offers scalable and modular architecture with easy deployment options.
What makes it unique:
🔗 Link: https://github.com/infiniflow/ragflow
 GraphRAG is a modular, graph-based Retrieval-Augmented Generation (RAG) system designed to enhance LLM outputs by incorporating structured knowledge graphs. It supports advanced reasoning with private data, making it ideal for enterprises and research applications.
GraphRAG is a modular, graph-based Retrieval-Augmented Generation (RAG) system designed to enhance LLM outputs by incorporating structured knowledge graphs. It supports advanced reasoning with private data, making it ideal for enterprises and research applications.
What makes it unique:
🔗 Link: https://github.com/microsoft/graphrag
 Haystack is an open-source AI orchestration framework for building production-ready LLM applications. It allows users to connect models, vector databases, and file converters to create advanced systems like RAG, question answering, and semantic search.
Haystack is an open-source AI orchestration framework for building production-ready LLM applications. It allows users to connect models, vector databases, and file converters to create advanced systems like RAG, question answering, and semantic search.
What makes it unique:
🔗 Link: https://github.com/deepset-ai/haystack
 STORM is an LLM-powered knowledge curation system that researches a topic and generates full-length reports with citations. It integrates advanced retrieval methods and supports multi-perspective question-asking, enhancing the depth and accuracy of the generated content.
STORM is an LLM-powered knowledge curation system that researches a topic and generates full-length reports with citations. It integrates advanced retrieval methods and supports multi-perspective question-asking, enhancing the depth and accuracy of the generated content.
What makes it unique:
🔗 Link: https://github.com/stanford-oval/storm
Retrieval Augmented Generation (RAG) faces challenges like ensuring data relevance, managing latency, and maintaining data quality. Some challenges are:
Platforms like SWIRL tackle these issues by not requiring ETL (Extract, Transform, Load) or data movement, ensuring faster and more secure access to data. With SWIRL, the retrieval and processing happen inside the user’s firewall, which helps maintain data privacy while ensuring relevant, high-quality responses. Its integration with existing large language models (LLMs) and enterprise data sources makes it an efficient solution for overcoming the latency and security challenges of RAG.